COUNT is an aggregate function in Oracle used for returning the count of rows in a column.
Syntax
The syntax of the Oracle COUNT function is as follows:
SELECT COUNT( [ALL /DISTINCT ]* expression) FROM table;
Here,
expression – It is column name whose rows we want to count.
Use of DISTINCT or ALL before the expression is optional. We use DISTINCT clause to specifically count only unique and non-repeating values in a row. ALL is used before expression for counting all rows.
If we don’t specify ALL or DISTINCT before the expression than COUNT function will count all rows by default.
And just like other aggregate functions like AVG, MAX, MIN even COUNT omits the NULL values while evaluating result.
Examples
1. Simple COUNT Example
We use the following query for counting the total number of rows in Employees table and since each row represents an employee, we can get to know the total number of employees in a table.
SELECT COUNT(*) FROM employees;
Result:
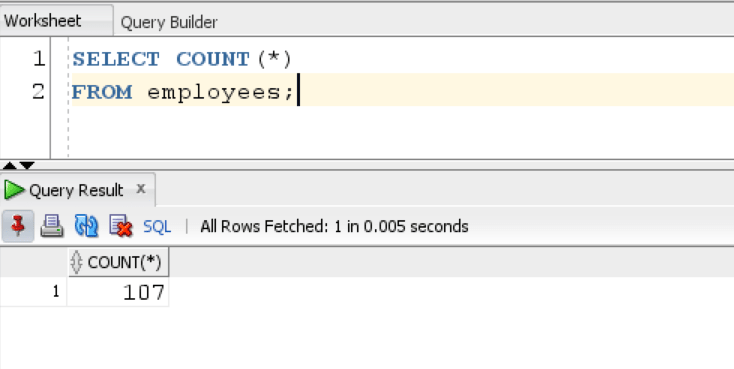
The query returns the total number of employees in Employee table.
If there are repeating values in a column, then we can also use DISTINCT clause which returns the count of unique rows in table. The query returns the count of distinct and non-null rows from the table.
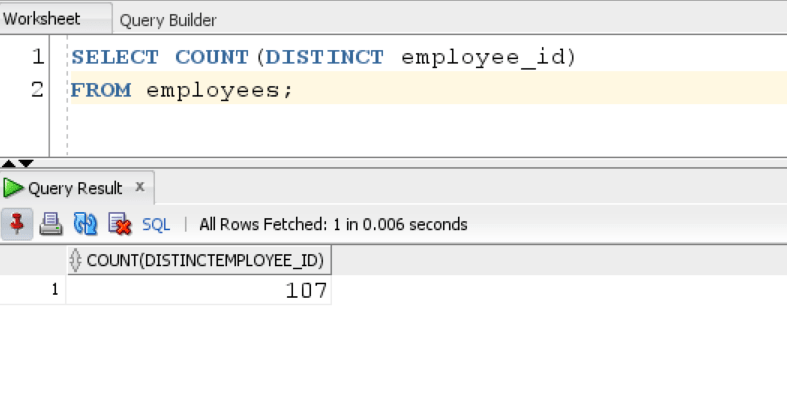
SELECT COUNT(DISTINCT employee_id) FROM employees;
Result:
Since, every employee ID is distinct we got the same count as above.
Let’s try to find the unique first names in the Employee table using this query:
SELECT COUNT(DISTINCT first_name) FROM employees;
Result:
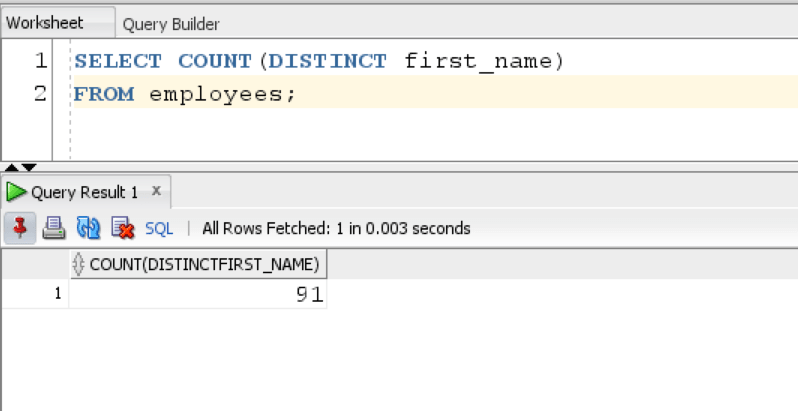
The query returns the distinct first names present in the employee table which is equal to 91. So there are 91 unique first names in the table.
If we want to find the count of all first names, then we can use the ALL clause. By default, all the COUNT queries gives the count of ALL rows and we don’t have to specify. But in this case, we are specifically mentioning that we want the total count of all first names in the table.
This query returns the number of all non-null rows in a table.
SELECT COUNT(ALL first_name) FROM employees;
Result:
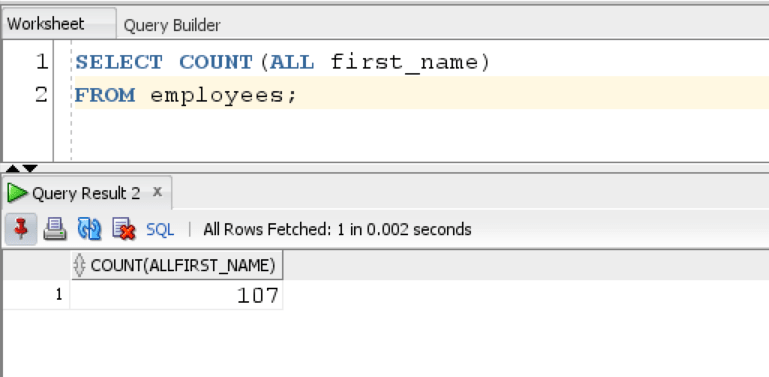
The query returns the count of ALL first names from the employee table which is equal to 107.
2. COUNT with WHERE
We can use the WHERE clause to further specify a condition. In this case, we want the count of rows belonging to department_id =100.
SELECT COUNT(*) FROM employees WHERE department_id = 100;
Result:
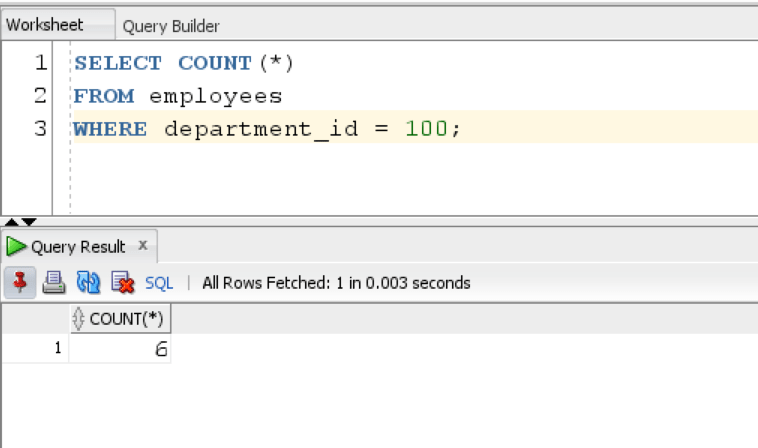
The query returns the count of all non-null rows where department_id=100.
3. COUNT with GROUP BY
Suppose, we want the count of rows in each department then we use the following query:
SELECT department_id, COUNT(*) FROM employees GROUP BY department_id ORDER BY department_id;
Result:
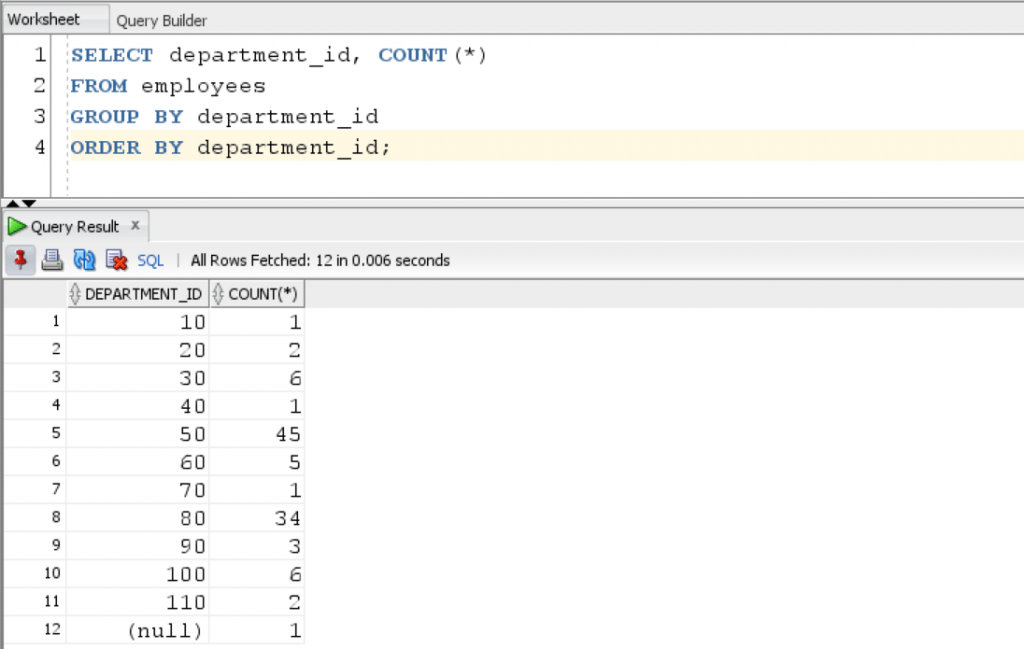
4. INNER JOIN
If we want to display the department name, then we would have to perform a join on Employees and Department Table. Lets see the following query:
SELECT department_name, COUNT(*) FROM employees INNER JOIN departments USING(department_id) GROUP BY department_name ORDER BY department_name;
Result:
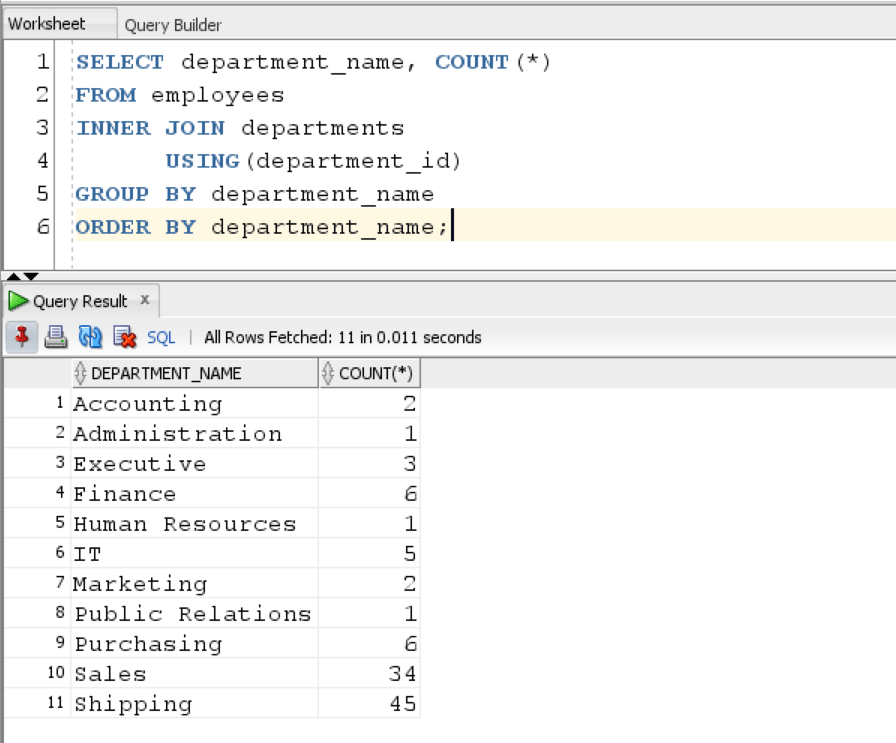
The query returns the total number of employees in each department and also shows the department name as we performed an inner join on departments and employees table.
5. HAVING
The COUNT can also be used with HAVING clause to further specify a condition. In this case, we only want to see the departments where the employee count is greater than 2.
SELECT department_name, COUNT(*) FROM employees INNER JOIN departments USING(department_id) GROUP BY department_name HAVING COUNT( employee_id ) > 2 ORDER BY department_name;
Result:
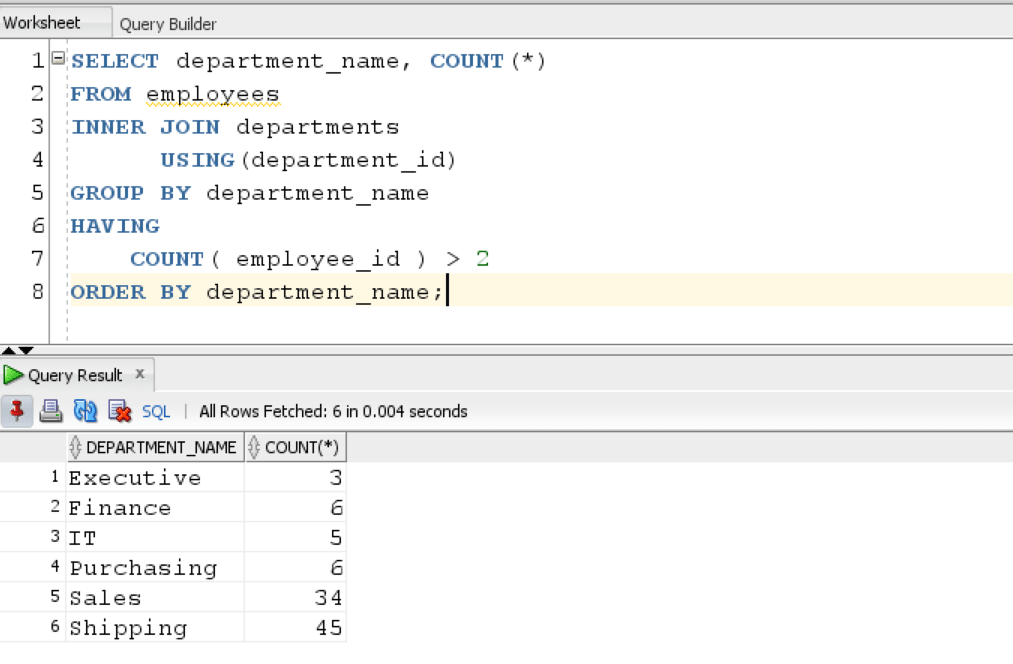
The query returns all the departments where the count of employees is greater than 2.
Let’s see one query which helps us to find which first names are being repeated more than once in the employee table.
SELECT first_name, COUNT( first_name ) FROM employees GROUP BY first_name HAVING COUNT( first_name )> 1 ORDER BY first_name;
Result:
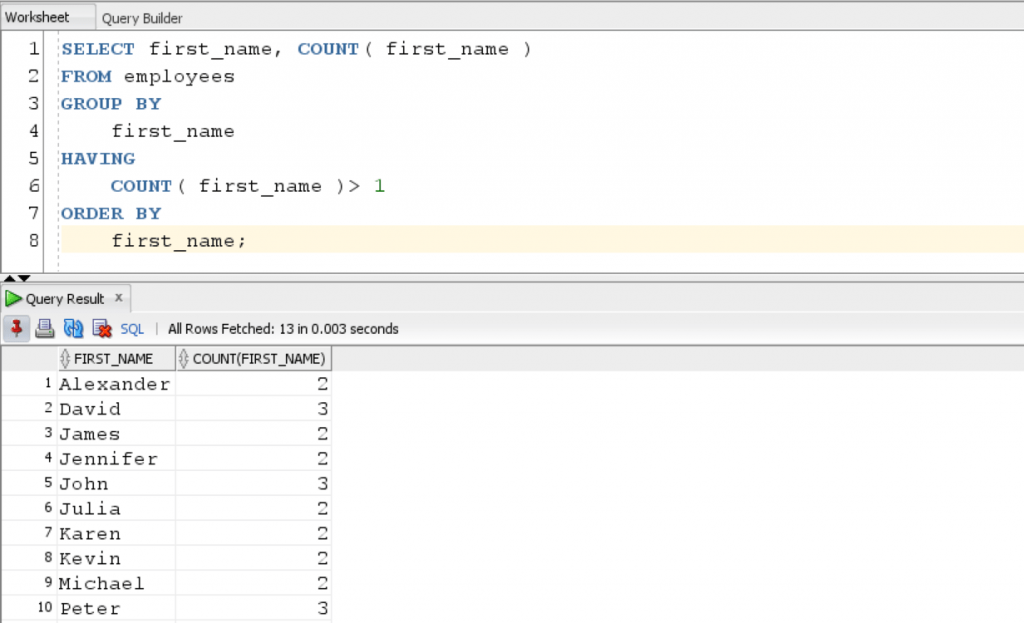
The query returns the first name of all employees which are repeated more than once and the number of times they are repeated.
In this tutorial, we learned how to use Oracle COUNT function in different scenarios.